Text Functions
Text functions evaluate or manipulate string data to perform operations like text modification, formatting, and extraction.
Combines multiple strings into a single text value.
Searches for a specified substring in a text value. If the substring is found, the function returns True, otherwise it returns False.
Determines if a text value ends with a specified substring. If the substring is found at the end of the text value, the function returns True, otherwise it returns False.
Returns the index where it first finds the specified substring within a string. Returns 0 if not found.
Returns True if the string matches the pattern. Case insensitive.
Returns the left portion of the string (the beginning), up to specified number of characters.
Returns the number of characters in a string, including spaces.
Returns True if the string value matches the pattern. Case sensitive.
Sets the string to a desired length by adding or removing characters at the front. Uses an optional fill character or defaults to extra spaces.
Converts a string to all lower case.
Removes leading spaces from a string.
Converts text to proper case, capitalizing the first letter of each word.
Returns the substring that matches a regular expression within a string.
Returns True if a string matches a regular expression.
Returns a string for a pattern and replaces it with a specified string.
Returns the result of repeating the string a specified number of times.
Replaces every instance of a specified string with a replacement string.
Reverses the order of characters in a string.
Returns the right portion of a string (the end), up to the specified number of characters.
Sets the string to a desired length by adding or removing characters at the end. Uses an optional fill character, or defaults to extra spaces.
Removes trailing spaces from the end of a string.
Splits the string into multiple parts at the positions of each appearance of the delimiter and returns the nth part of the string at the specified position.
Determines if a string starts with the specified substring. Returns True or False.
Removes both leading and trailing spaces from a string.
Converts a string to upper case (all capital letters).
Concat
The Concat function combines text strings.
Usage
Function arguments:
string_1
(required) First string to combine in the sequence.
string_2+
(optional) Additional strings to combine in the sequence.
Concat doesn't automatically add spaces between strings. To add a space in the output, include
" "as its own argument.To include a number or date value as a string, place quotation marks around the value (
"2024-01-01").To treat values in a number column as text strings, enclose the column name in the Text function (
Text([Column])).
Example
Returns queenbee.
Returns queen bee.
Combines a column of names with their corresponding ID numbers.
When the newline character () is added as an argument, Concat generates the subsequent argument on a new line. To view the output on separate lines, ensure Wrap text formatting is applied to the column.
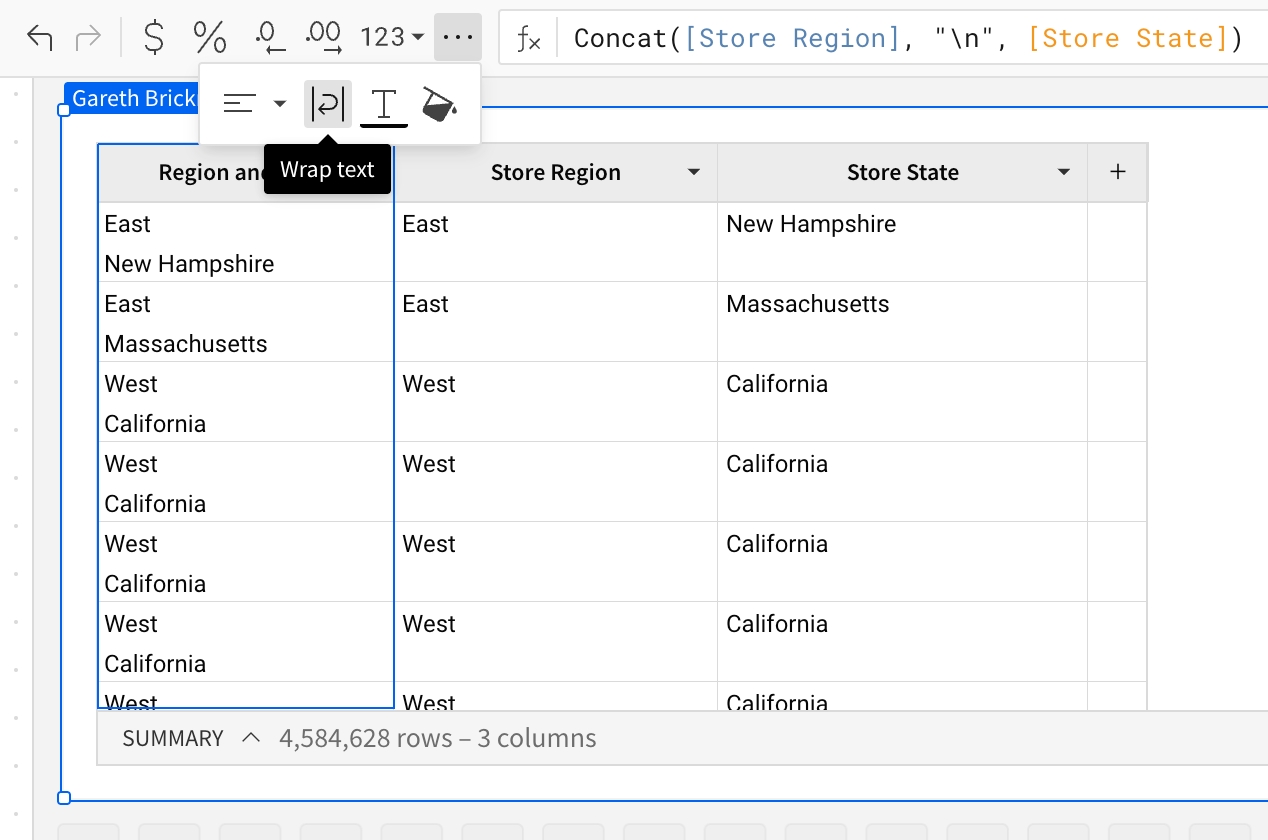
Contains
The Contains function searches for a specified substring in a text value. If the substring is found, the function returns True, otherwise it returns False.
Syntax
Function arguments:
string
A text value or column of text values to search.
Individual text value input (not column input) must be enclosed in parentheses. For example,
"My name is Bob".Can only reference a column that contains text data.
substring...
One or more substrings or columns of substrings to search for in the text value.
Individual substring input (not column input) must be enclosed in parentheses. For example,
"is Bob".Multiple substrings must be input as separate arguments. For example,
"name", "is Bob"or[ColumnA], [ColumnB].
Notes
Arguments are case sensitive. To bypass case sensitivity, use the Lower function to convert the arguments to lowercase as needed.
When the multiple substring arguments are included, the function returns
Trueif at least one substring is found.
Examples
Example 1
Returns False because "to sig" (with a lowercase 's') isn't a substring in "Welcome to Sigma."
Example 2
Converts the string argument to all lowercase characters and returns True because "to sig" is found as a substring in "welcome to sigma."
Example 3
Returns True when the city name (text value in the City column) is found as a substring in the station name (text value in the Station column). Otherwise, the function returns False.
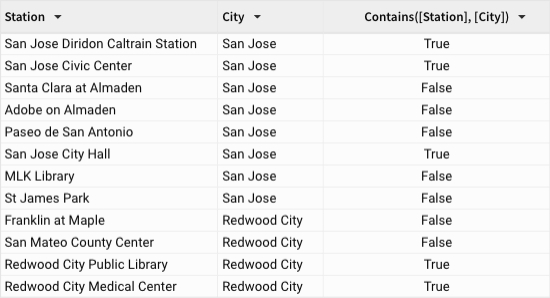
Example 4
Returns True when either "Digital Camera" or "DSLR" is found as a substring in the product name (text value in the Product Name column). Otherwise, the function returns False.
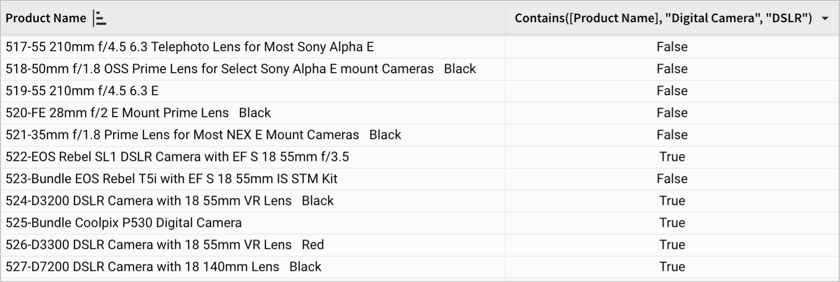
EndsWith
Returns True if a string ends with a substring.
Usage
EndsWith(string, substring)
string (required) The text to search.
substring (required) The text to search with.
📘EndsWith is case-sensitive. To create a search that is not case-sensitive, combine EndsWith with Lower.
Example
EndsWith("Jane Doe", "oe")
Returns TRUE
EndsWith(Lower("JANE DOE"), "oe")
Returns TRUE
Find
Returns the index at which a substring is first found within a given string. If the substring is not found, the result is 0.
Usage
Find(string, substring)
string (required) The text to search.
substring (required) The text to search with.
Find is case-sensitive. To create a search that is no case sensitive, you can combine Find with Lower.
Example
Find("milk+cookies", "cook")
Returns 6
The string “cook” starts on the 6th letter.
Find("milk+cookies", "chocolate milk")
Returns 0 because the substring is not found.
Find("Abe Lincoln", "lincoln") = 0
Returns 0 because the substring is not found. Find is case-sensitive
Find(Lower("Abe Lincoln"), "lincoln")
Returns 5 because the substring is found in the lowercased string.
Find(“San Francisco County”, “ “)
Returns 4 because Find searches from left to right and returns the first instance of the substring.
ILike
Returns true if the string value matches the case-insensitive pattern.
Usage
ILike(string, pattern)
string (required) The text string that is being searched.
pattern (required) The search pattern. An '_' matches any character. A '%' matches any sequence of zero or more characters.
Examples
Try it in Sigma Sample Data
In Sigma's sample baby name data, the following formula returns true for values in the [Name] column that include “em”, like "Emma", “Gemma” and “Jeremy”.

Left
Returns a substring that begins at the start of a given string.
Usage
Left(string, number)
string (required) The string from which a left substring will be returned.
number (required) The desired length of the returned substring. A negative number removes the number of characters from the end of the string.
Example
Left("Dec. 12, 1950", 3)
Returns “Dec”
Left("St. Louis", 20)
Returns “St. Louis”
If number is greater than the length of string, the result is the original string.
Left("San Francisco", -5)
Returns “San Fran” because it is the result of removing 5 letters from the end.
Len
Like
Returns true if the string value matches the case-sensitive pattern.
Usage
string (required) The text string that is being searched.
pattern (required) The search pattern. An '_' matches any character. A '%' matches any sequence of zero or more characters.
Examples
Try it in Sigma Sample Data
In Sigma's sample baby name data, the following formula returns true for values in the [Name] column that include “em”, like “Gemma” and “Jeremy”. The Like function is case-sensitive, so string values such as "Emma" returns false.

LPad
Prepends a pattern to or truncates a string to the desired length.
Usage
text (required)- The string, or column of strings, to pad or trim to the desired length.
length (required)- The length of the returned string.
fill (optional)- The character with which to pad the text. Defaults to space.
Example
Returns the Product Family column trimmed to a length of 4

Returns "-----space"
Returns "Analytics "
Lower
Converts a given string to lowercase.
Along with Upper and Proper, this is useful for bypassing case-sensitivity in other Text functions.
Usage
Lower(text)
text (required) A string or column where each row contains a string.
Example
Lower("PLEASE KEEP QUIET IN THE LIBRARY")
Returns “please keep quiet in the library”
LTrim

MD5
Mid
Returns a substring defined by offset and length.
Usage
string (required) The string to extract a substring from.
start (required) The index of the first letter of the extracted substring. The first character of the given string is treated as having index 1.
length (optional) The length of the segment to extract. If length is not given, or if the provided length is longer than the remaining source string, the total remaining string will be returned.
Example
Returns “n Doe”
Returns “oh”
Returns “”, an empty string.
Proper
The Proper function converts text to proper case, which capitalizes the first letter of each word and renders all remaining letters in lowercase.
Syntax
Function arguments:
string (required) - a text string or column to reference when converting text to proper case
🚧If the string argument references a column, the column must contain text values. Other data value types result in an invalid formula.
Examples
Returns Apples And Oranges.
Returns the proper form of the text value in the Product Family column.
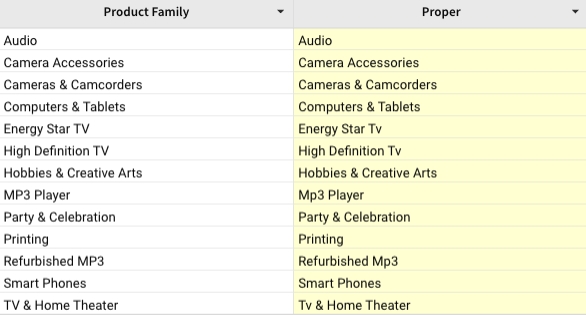
RegexpExtract
The RegexpExtract function returns the substring that matches a regular expression within a string.
If the regular expression contains a capture group ((...)) and there are one or more matches for that capture group, Analytics Pro returns the first capture group across all matches. Otherwise, Analytics Pro returns the full regular expression.
Usage
Function arguments:
string (required): The string to search
substring (required): The substring to extract with.
position (optional): The index of the match to return.
📘When the regular expression contains a slash, quotation or other special character, use a backslash (\) to escape the special character. Regexp can vary based on the database. Check the documentation of the database you use to find the correct syntax.
Examples
Example 1:
Extracts the first match of numeric characters in the string. No position is specified so position defaults to 1.

Example 2:
Extracts the second match of numeric characters in the string.

Example 3:
Extracts the second match of alphabetical characters in the string.

Example 4:
Extracts the second match, day of date, of the 2-digit character group in the date.
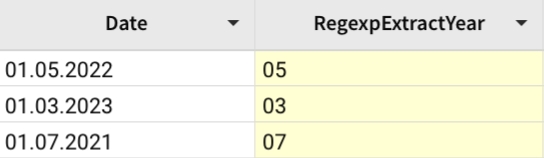
RegexpMatch
Returns True if a string matches a regular expression.
Syntax
RegexpMatch(string, pattern)
stringRequiredThe string to search.patternRequiredThe pattern to match within the subject.
📘When the regular expression you want to use contains a slash, quotation or other special character, you will need to use a backslash (\) to escape the special character. Regexp can vary based on the databases. Check the documentation of the database you use to find the correct syntax.
Examples
Example 1:
Check if a name starts with an uppercase letter, followed by one or more lowercase letters, and then has another uppercase letter followed by one or more lowercase letters.

Example 2:
Check if a string matches the social security pattern 'xxx-xx-xxxx'
Returns true.
Example 3:
Check if a string matches the phone number pattern '(xxx) xxx-xxxx'
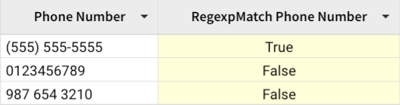
Example 4:
Check if an address starts with a numeric characters.
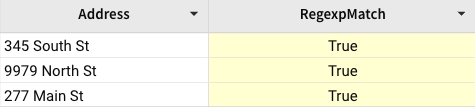
RegexpReplace
The RegexpReplace function searches a string for a pattern and replaces all matches with the replacement string. If no matches are found, the original string is returned.
Syntax
Function arguments:
string (required): The string to search.
pattern (required): The pattern to extract with.
replacement (required): String to replace the sought pattern.
📘When the regular expression you want to use contains a slash, quotation or other special character, you will need to use a backslash (\) to escape the special character.Regexpcan vary based on the databases. Check the documentation of your database to find the correct syntax.
Examples
Example 1:
Replaces every space between digits and digits preceding "mm" with a dash to indicate the range of camera lenses.

Example 2:
Transforms a phone number to (xxx) xxx-xxxx formatting.
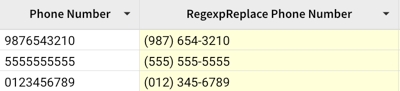
Example 3:
Replaces every character before the comma with the city in proper form.

Example 4:
Removes all punctuation marks in a string.

Example 5:
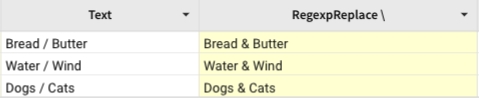
Replaces the slash with "&".
Repeat
The Repeat function returns the results of repeating a string a specified number of times.
Syntax
Repeat has the following arguments:
string
Required
The string that the function repeats number
number
Required
The number of times the string repeats. The zero, 0, and negative values both return a NULL string.
Examples
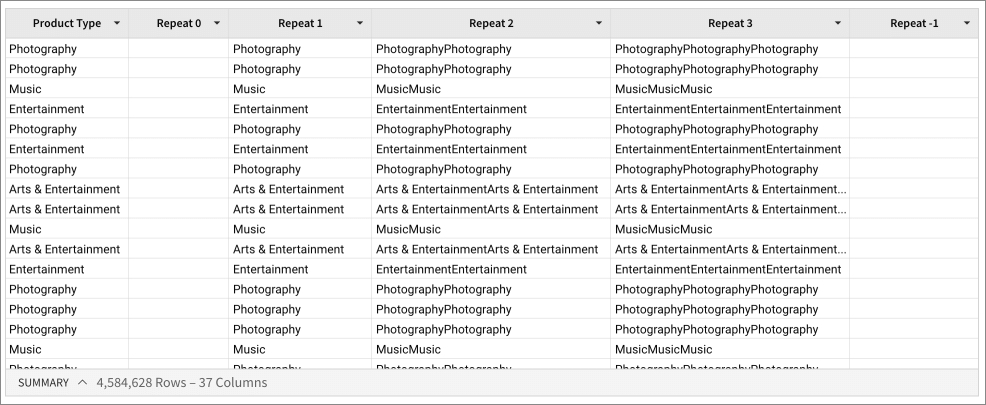
The Repeat function returns the following values for the Product Type column:
Replace
The Replace function searches through a input string for a substring and replaces every instance of it with a replacement string.
This is useful for standardizing alternative abbreviations and names, fixing common misspellings, changing one delimiter for another, and selectively removing particular substrings.
Usage
string (required)- String to be searched and modified.
substring (required)- Substring to be found and replaced.
replacement (required)- String to replace the substring.
Examples
Returns: "San Francisco County"
Replace("File Name"," ","")
Returns: "FileName"
Using an empty string as your replacement string allows you to remove every instance of the substring
When applied to the [Order Replaced] column, returns:

Reverse
The Reverse function reverses the order of the characters in a string.
This function is useful for making text functions that normally work forwards from the beginning of a string, such as Mid or Substring, to instead work backwards from the end of the string.
Usage
text (required)- Text or a column of text that you want to reverse.
Example
Returns “stressed”

Right
The Right function returns a substring from the end of a string. This substring will be the last n characters of the string, where n is the argument number.
This is useful to extract a relevant piece of a string that is at the end with a constant length.
Usage
Right(text, number)
text (required)- The string from which a right substring will be returned
number (required)- The desired length of the returned substring.
Examples
Right(“Jane Doe”, 5)
Returns: “e Doe”
Right("Apartment 217",3)
Returns: "217"
RPad
The RPad function makes a string a desired length by either adding or removing characters at the end of the string. If the string is too long, the string will be truncated by removing characters. If the string is too short, the string will be padded by adding fill characters.
It's useful for standardizing the length of strings as inputs for other text functions dependent on length, such as Mid. It's also useful for standardizing text to be more readable.
Usage
text (required)- The string to pad to the desired length.
length (required)- The length of the returned string.
fill (optional)- The fill character with which to pad strings shorter than the length. Defaults to space.
Example
Returns: "space-----"
Returns: "Analytics "
Returns:
RTrim

SplitPart
The SplitPart function splits the string into multiple parts at the positions of each appearance of the delimiter in the string ... then returns a single part of the string. Specifically, it returns the nth part, where n is the position.
SplitPart is useful for extracting portions of a string defined by a repeating pattern, such as spaces between words or delimiters in an array.
Usage
string (required)- The source string to be split.
delimiter (required)- The string to split with.
position (required)- The index of the part to return. When searching the string for the delimiter, the string is broken into parts each time the delimiter is found. These parts are numbered from left to right, starting with 1. Negative numbers for the index will start counting the index from the right.
Example
Returns: “ index3”
Returns: “quick”
Returns: “fox”
A negative position starts counting the index from the right.

StartsWith
Returns true if a string starts with a specified substring.
Usage
StartsWith(string, substring)
string (required)- The string to search.
substring (required)- The substring to search with.
📘EndsWith is case-sensitive. To create a search that is not case-sensitive, combine EndsWith with Lower.
Example
StartsWith("Jane Doe", "Ja")
Returns TRUE
Substring
The Substring function is an alias of Mid. Returns a substring defined by offset and length.
Usage
string (required) The string to extract a substring from.
start (required) The index of the first letter of the extracted substring. The first character of the given string is treated as having index 1.
length (optional) The length of the segment to extract. If length is not given, or if the provided length is longer than the remaining source string, the total remaining string will be returned.
Example
You can use this function in combination with the Find function to identify mentions of a given word in a transcript and output the surrounding text.
For example, given a column Transcript, retrieve 200 characters of text after the word "Space":
Returns a string of text excerpted from the transcript, starting from the word Space.
To retrieve the text in the transcript before and after the given word, you can use this function twice and concatenate the results with the Concat function or the & character. For example, given a column Transcript, retrieve 200 characters before and 200 characters of text after the word "Space":
Returns a string of text excerpted from the transcript, starting 200 characters before the word Space, and ending 200 characters after the word Space.
For example, extract 10 characters from a given string, starting at index 4:
Returns "n Doe".
As another example, extracting data at index 4 for a string length of 3 characters returns an empty string:
Returns "", an empty string.
